Database names are the level-5 HTM node names

We use a k-d tree to index the u,g,r,i,z flux components of the SDSS filter data. See the description of the Color Partitioning Scheme by I. Csabai.
The Flux Index is a binary tree. At each step there is a certain split given by a plane in Flux Space (5-d space, using u,g,r,i,z as axes). The splits may be chosen differently for different regions of the sky, so we will have several Flux Indices. Since reddening is the major factor influencing the light from far-away objects, now we think of having 8 different stripes of Flux Indices each for north and south of the Galactic Plane. The mapping (which sky triangle is corresponding to which flux index) is also part of the Flux Index.
The first split is special and does not correspond to a plane but to a whole region of the flux space. The colors of the objects will usually fall into a very specific region. Only special objects will fall outside the scheme (like Quasars) and they will be sparsely distributed. All these outliers will have a separate index and the first split in the index indicates the split between outlier and normal objects.
Names of Flux Index leaves are given by the direction of their split and since it is a binary tree, we get names like "101011101". These names are used as container names in the databases.
During intersection, the Flux Index may alter a Flux Domain to simplify
its structure.
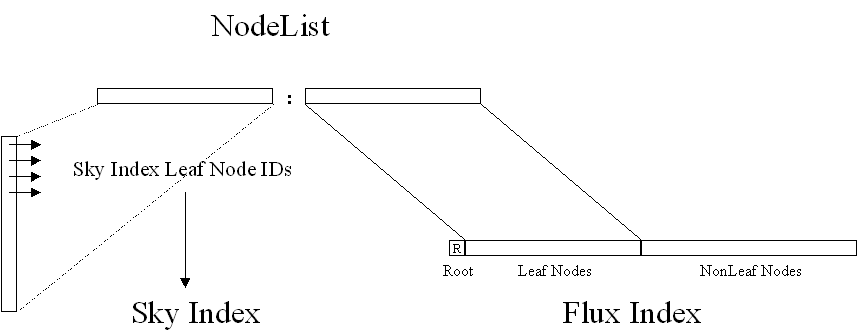
For the Sky Index we cannot arrange the Tree in such a manner, so we need to generate an array where the IDs of the Sky Leaf Nodes are ordered in the same way as the bits in the Sky BitList. The i'th bit in the BitList finds the ID of its Sky Leaf Node through the i'th pointer in this array.